


👋 Welcome to the first edition of State of AI: Monthly Paper Deep Dive.
Each month, we’ll take one standout AI research paper and break it down clearly, concisely, and without the jargon. Whether it’s a breakthrough in training efficiency, a new benchmark-beating model, or a clever architectural twist, we’ll help you understand why it matters and how it works.
This inaugural deep dive is free for all readers. Starting next month, future editions will be exclusive to paid subscribers, so if you find this valuable, consider upgrading to keep getting the good stuff.
Let’s get into it!
Introduction
Imagine you’re training a brilliant but forgetful assistant. They know a lot, but sometimes their knowledge is outdated or incomplete. So, you let them Google answers except every search costs money, and half the results are junk.
That’s the problem today’s LLMs face. They’re trained on huge datasets, but their knowledge is frozen in time. When asked about new or obscure facts, they hallucinate. Retrieval-Augmented Generation (RAG) adds web access, but it introduces new chaos: high costs, noisy data, and unstable learning.
Now, researchers at Alibaba’s Tongyi Lab have come up with a solution that borders on sci-fi: ZeroSearch, a framework that lets AIs learn how to search without ever going online.
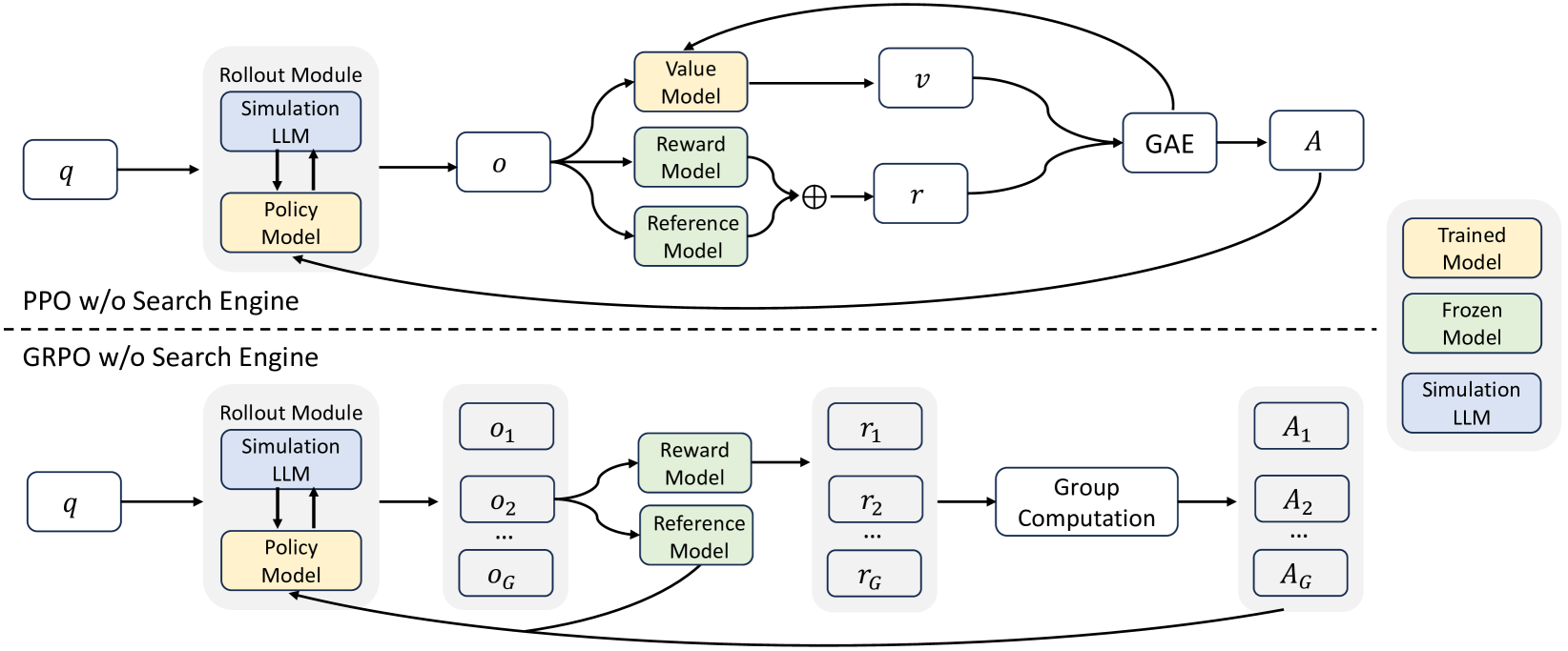
The ZEROSEARCH framework uses RL algorithms (PPO and GRPO) with a simulated search environment. This removes the need for search engine APIs.
And the kicker? It performs better than models using real search engines.
🔍 Why Real-World Searches Fail AI
Training an AI with real web search results sounds ideal—until you realize:
Search results are inconsistent: One minute you get Wikipedia gold, the next it’s blogspam. This makes reinforcement learning unstable.
Every query costs money: Search APIs aren’t cheap. At scale, costs skyrocket.
There’s no difficulty ramp: You can’t ease a model into hard reasoning when real-world data is randomly challenging or irrelevant.
Real-world retrieval is messy, noisy, and unpredictable. And worst of all, it's not repeatable—making debugging and benchmarking nearly impossible. Imagine running an experiment and then failing to reproduce it simply because Google decided to update its index.
RAG and agent-based search help, but they rely on brittle integrations and still depend on external APIs. They’re expensive, opaque, and hard to debug.
🔧 The Solution: ZeroSearch’s AI-Powered Illusion
ZeroSearch flips the script: rather than teaching LLMs to rely on external APIs, it teaches them to interact with a simulated search engine, another LLM fine-tuned to act like the internet.
Step 1: Build a Fake Google
They took a smaller LLM (3B, 7B, or 14B) and fine-tuned it to respond like a search engine. It returns five results per query, and here’s the twist:
Some are accurate
Some are misleading
The simulation LLM is trained with both correct and incorrect answers, conditioned via prompt keywords (“useful” or “noisy”).
This duality is key as it forces the main model to develop critical reasoning skills. Just like a human scanning a mix of sources, the model must learn to identify high-quality information.
Step 2: Train the Main Model With Curriculum Learning
The main LLM (the “student”) interacts with the simulated engine using a structured format:
<think> reason through problem </think>
<search> generate search query </search>
<information> receive simulated results </information>
<answer> provide final answer </answer>At first, the student only sees clean, accurate documents. As training progresses, noise is introduced gradually. This technique—known as curriculum learning—is a staple in human education and increasingly popular in machine learning.
This forces the student to learn how to:
Generate effective search queries
Sift signal from noise
Decide when to stop searching and answer
Handle ambiguity and conflicting information
The noise is controlled mathematically, increasing according to a curriculum:
p_i = ps + ((b^(i/m) - 1) / (b - 1)) * (pe - ps)This formula ramps up noise over training steps, starting easy and growing difficult, much like raising the temperature during adversarial learning.
Step 3: Reward Accuracy, Not Guessing
Rather than punishing every imperfection, ZeroSearch uses the F1 score to balance precision and recall. This prevents the model from spamming long, vague answers and encourages clarity.
The choice of reward metric is crucial. Exact match (EM) encourages overly conservative answers. F1, on the other hand, rewards partial correctness in a nuanced way. This lets the model explore and learn without gaming the reward function.
📊 What Happened When They Tested It
ZeroSearch was evaluated on 7 QA datasets (like NQ, TriviaQA, and HotpotQA) and benchmarked against strong baselines like RAG, Search-R1, and direct prompting. The results:
Outperformed real search engines: A 7B simulation LLM matched Search-R1; the 14B version beat it.
Worked across model types: Base and instruction-tuned models both improved.
Trained more efficiently: Fewer interactions, higher reward over time.
Even more impressive? The models showed steady performance improvement while using fewer search “turns” over time, an indicator of learned efficiency.
🔍 Deep Dives: Ablations and Stability
Simulation Size Matters: Bigger simulation LLMs (14B) generate more realistic responses, enabling better student learning. They reduce hallucinations and improve grounding.
Loss Masking Is Key: By ignoring gradients from the simulation’s outputs, the model avoids instability. Removing this drops F1 by 5+ points and leads to noisy convergence.
Easy-First Curriculum Beats Hard-First: Starting training with noise leads to poor convergence. Let the model crawl before it runs.
The paper also compared PPO vs GRPO, finding GRPO slightly more stable in practice—though both were compatible with the framework.
💰 Cost Breakdown: Real vs Simulated

ZeroSearch slashes the cost of training by an order of magnitude—while also improving outcomes. For cash-strapped teams or researchers without API access, this lowers the barrier to entry significantly.
And unlike Google, your simulation LLM won’t rate-limit you, change its behavior without notice, or get blocked due to geography.
🌍 Why This Changes the Game
Massive Cost Savings: No API fees. All local compute.
Stable Training: The curriculum and loss masking create a predictable learning curve.
Open Access to Research: Any lab can now train a “search-capable” model without needing deep pockets.
It also redefines “search” as a learned behavior, not a hard dependency.
And perhaps more importantly—it reframes what it means for a model to “search.”
If AI can fake search this well, what else can it simulate? Law? Medicine? Programming?
🔮 The Big Picture
ZEROSEARCH is a rethinking of how LLMs can acquire external knowledge.
It replaces fragile, expensive, real-world dependencies with controllable, synthetic experiences where difficulty, noise, and feedback are all programmable.
It’s not hard to imagine future models trained on simulated legal queries, medical knowledge bases, or even customer service logs, crafted to challenge, not just inform.
Sometimes, the best way to teach a model to navigate the real world is to first master a world we design.
And that’s what makes ZeroSearch so exciting.