


Language model training has always been framed around compute as the scarce resource. Scaling laws like those in Kaplan et al. or Chinchilla assume that if you have more compute, you should spend it by scaling both model size and dataset size. But this assumption breaks when data growth slows down.
The Stanford team wrote a paper which points out that web-scale text grows by only about 1.03× per year, while pre-training compute grows at 4× per year. That mismatch guarantees a regime where models can’t keep consuming fresh data, even if we can throw more FLOPs at them. The bottleneck shifts: not enough new tokens to train on.
So the central question is:
How should we pre-train models when compute is effectively infinite, but high-quality data is fixed?
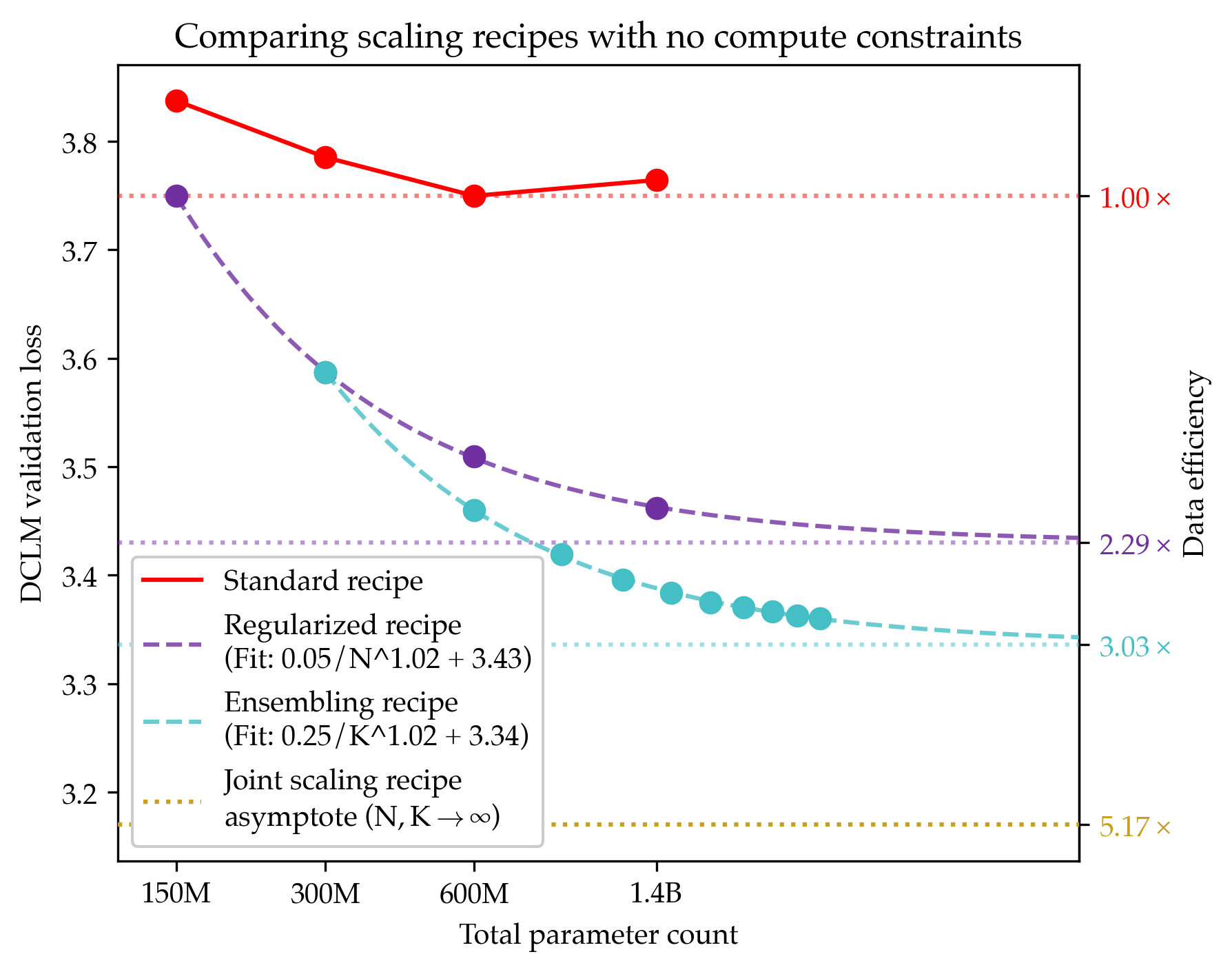
Standard approaches fail under data limits
The first step was to revisit common recipes used when data is scarce:
Keep reading with a 7-day free trial
Subscribe to State of AI to keep reading this post and get 7 days of free access to the full post archives.