

Benchmarking Open Source Language Models
Analysis of Key Metrics from the OpenLLM Leaderboard: AI2, HellaSwag, MMLU, TruthfulQA, Winogrande, GSM8k
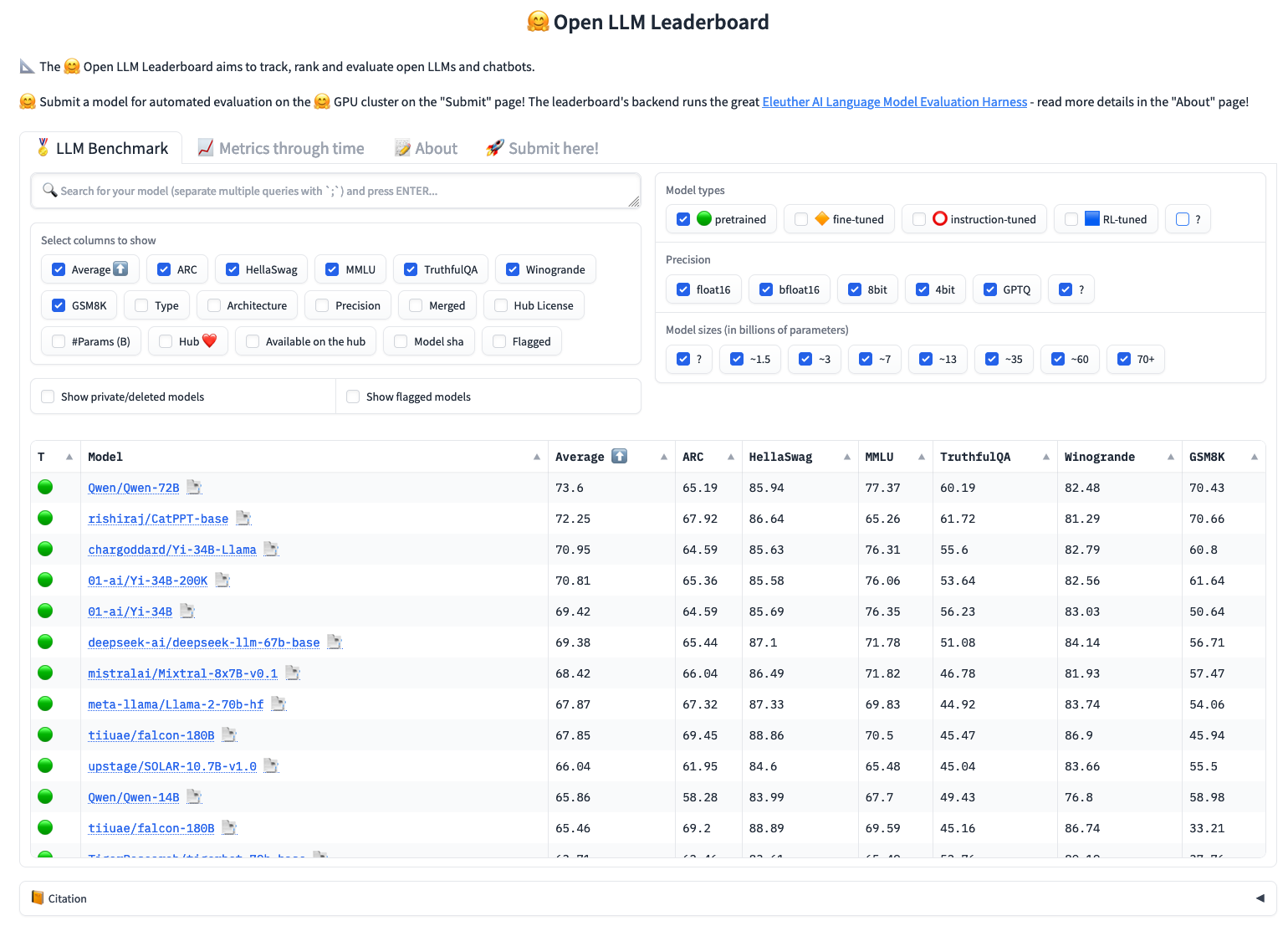
This post offers an in-depth analysis of open-source language models (LLMs) based on seven key benchmarks from the OpenLLM Leaderboard on Hugging Face, using the Eleuther AI Language Model Evaluation Harness. This harness is a unified framework designed to test generative language models across a wide range of evaluation tasks, providing a standardized approach to benchmarking.
We focus on the following benchmarks: AI2, HellaSwag, MMLU, TruthfulQA, Winogrande, and GSM8k. These benchmarks are critical for assessing language models in tasks related to understanding and generating human language, offering insights into their performance and capabilities.
The summaries in the following sections are aimed at presenting clear and concise findings from research papers associated with each benchmark. Our objective is to provide an informative overview that highlights the methodologies, results, and implications of these studies, thereby helping readers gain a comprehensive understanding of the current landscape of LLMs and the challenges they encounter in diverse scenarios.
Structured to deliver straightforward and informative content, this post caters to readers interested in the technical aspects of language models, aiming to keep them updated with the latest advancements in AI and language processing.
Best Regards
Reading Time: 17 Minutes
Contents
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
HellaSwag: Can a Machine Really Finish Your Sentence?
Measuring Massive Multitask Language Understanding
TruthfulQA: Measuring How Models Mimic Human Falsehoods
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Training Verifiers to Solve Math Word Problems
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Authors: Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, Oyvind Tafjord
Source and references: https://arxiv.org/abs/1803.05457
Introducing the AI2 Reasoning Challenge (ARC)
The authors present the AI2 Reasoning Challenge (ARC), a new question set aimed at encouraging advancements in AI research for more complex question-answering tasks. This dataset consists of 7,787 natural, grade-school science questions specifically chosen to require more comprehensive knowledge and reasoning than previous question-answering datasets such as SQuAD or SNLI. The ARC questions are divided into a Challenge Set and an Easy Set, with the Challenge Set containing only questions that were answered incorrectly by both a retrieval-based algorithm and a word co-occurrence algorithm.
Why ARC?
Current question-answering datasets have primarily focused on "retrieval-style" tasks where surface-level cues were sufficient to find answers, which hasn't fostered progress for questions that demand commonsense knowledge, advanced reasoning, or deeper linguistic understanding. The ARC dataset, comprising natural science questions from standardized tests, attempts to fill this gap by selecting difficult questions that can't be answered by simple baselines—encouraging research on novel methods that can handle complex questions.
The ARC Dataset
The dataset includes 7,787 multiple-choice questions with varying grade levels (ranging from 3rd to 9th grade). The authors devised an operational definition for "Challenge questions" as those that were answered incorrectly by both a retrieval-based algorithm and a word co-occurrence algorithm. This allowed for a practical filter that distinguished between relatively easy and more challenging questions.
Question Types in the ARC Challenge Set
The dataset contains questions that span across various types of knowledge and reasoning styles. Some categories include definitions, structure, spatial/kinematic relationships, qualitative reasoning, and comparisons. The Challenge Set contains questions that demand a higher level of understanding compared to the Easy Set.
The ARC Corpus
Alongside the question set, the authors also provide the ARC Corpus, a collection of 14 million science-related sentences mined from the web that address the knowledge needed to answer the Challenge questions. This corpus is provided as an optional resource, and systems are not restricted to this corpus alone.
Baseline Models and Their Performance
The authors tested several baseline models on the ARC Challenge Set, including top-performing neural models from SQuAD and SNLI tasks. However, none of these models managed to significantly outperform a random baseline on the Challenge Set, highlighting the difficulty of the task. The authors then posed the ARC as a challenge to the research community to develop models that perform better on the dataset's more complex questions.
The Potential of ARC
The AI2 Reasoning Challenge offers a much-needed shift in focus for the AI research community. By emphasizing advanced knowledge and reasoning, the ARC dataset pushes the boundaries of current question-answering paradigms and drives the pursuit of linguistic understanding and reasoning capabilities in AI. By making both the questions and the supporting ARC Corpus publicly available, the authors invite researchers to tackle this challenging problem head-on, paving the way for more sophisticated AI systems capable of understanding complex, real-world questions.
HellaSwag: Can a Machine Really Finish Your Sentence?
Authors: Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, Yejin Choi
Source and references: https://arxiv.org/abs/1905.07830
The Intriguing Question of Commonsense Inference
Natural Language Processing (NLP) researchers have long sought to build models capable of making commonsense inferences. Very recently, a near-human-level performance was reached by BERT, a model introduced by Devlin et al. (2018). The question arises: does this mean that machines can now perform human-level commonsense inference? The authors of this paper challenge that assumption by introducing HellaSwag, a new challenge dataset that explores the limits of even state-of-the-art models.
Introducing HellaSwag, a Tough Challenge for NLP Models
To better understand the capabilities of models like BERT, this paper proposes HellaSwag, a dataset that pushes the boundaries of commonsense inference. The authors use a technique called Adversarial Filtering (AF) to iteratively generate hard examples for the models. By leveraging state-of-the-art generators, discriminators (e.g., BERT), and high-quality source text, they create a dataset that is easy for humans (95% accuracy) but challenging for machines (48%).
One crucial hypothesis is that when machine-generated sentences feature a certain length and complexity, humans can easily recognize them as nonsensical while models struggle to do so. HellaSwag's dataset construction explores this "Goldilocks" zone, where generated sentences are both perplexing to models and easy for humans to judge.
Examining BERT's Understanding of Commonsense Inference
The authors explore just how much innate knowledge BERT has about the commonsense inference task. They evaluate BERT's performance across different training dataset sizes, finding that it requires tens of thousands of examples to approach human performance. Moreover, they observe that BERT's performance is strongly influenced by the structure of the text and its length.
Their analysis indicates that BERT primarily learns to detect distributional stylistic patterns during finetuning and that it can adapt relatively easily to unusual text structures, such as shuffled words in sentences. This suggests that BERT is more like a rapid surface learner rather than a deep reasoner for a particular dataset.
Creating a New Commonsense NLI Dataset: HellaSwag
The key to constructing a challenging dataset like HellaSwag is employing high-quality generators, discriminators, and data sources. For this task, the authors turn to video captions from the ActivityNet dataset and articles from WikiHow, which provide diverse and complex contexts for the examples.
Using Adversarial Filtering, they generate difficult examples that can confuse state-of-the-art models. Surprisingly, they find that both BERT and human performance improve on the ActivityNet and WikiHow datasets as the length of generated sentences increases. This indicates that longer sentences provide more opportunities for models and humans alike to detect mistakes.
A Future of Verified Progress in NLP
This research highlights the need for adaptive and evolving benchmarks in NLP. As models like BERT improve and tackle existing benchmarks, it becomes crucial to develop new datasets that explore the limits of their capabilities.
The authors advocate for a co-evolving approach, wherein benchmarks and state-of-the-art models both grow and adapt in adversarial ways. This process ensures that NLP models continue to face and overcome increasingly challenging tasks, demonstrating genuine progress in understanding and reasoning.
In conclusion, while BERT and similar models have made impressive strides in NLP, they still have a long way to go in developing true commonsense reasoning capabilities. This paper presents the HellaSwag dataset as a step toward understanding these limitations and driving future progress in the field.
Measuring Massive Multitask Language Understanding
Authors: Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhard
Source and references: https://arxiv.org/abs/2009.03300
A New Test for Text Models
Machine learning researchers have designed a new benchmark to measure text models' multitask accuracy. Named "Massive Multitask Test," it covers a wide range of 57 tasks, including elementary mathematics, US history, computer science, law, and more. Models must possess extensive world knowledge and problem-solving ability to achieve high accuracy on this test.
Models Struggle with Knowledge Application
Recent advances in Natural Language Processing (NLP) models have enabled near human-level performance on many popular benchmarks. However, when it comes to understanding language at a professional level, these models still struggle. The researchers found that while most recent models have near random-chance accuracy, the largest GPT-3 model (175 billion parameters) improves over random chance by almost 20 percentage points on average.
Lopsided Performance and Lack of Expertise
Models like GPT-3 exhibit lopsided performance, excelling in some tasks while performing poorly in others. Notably, they perform near-random accuracy on socially important subjects like morality and law. The best models still need substantial improvements to reach expert-level accuracy on every one of the 57 tasks in the Massive Multitask Test.
Evaluating and Identifying Shortcomings
The researchers propose using the Massive Multitask Test to analyze models across numerous tasks and to identify crucial shortcomings. The test's comprehensiveness can pinpoint a model's blind spots. It also measures how well a model can learn from its vast pretraining, applying its knowledge across different domains.
Developing a Massive Multitask Test
The Massive Multitask Test spans subjects across STEM, humanities, social sciences, and more. It ranges from elementary to advanced professional levels, evaluates world knowledge and problem-solving ability, and covers traditional areas as well as specialized ones like law and ethics. The granularity and breadth of the subjects make the test ideal for identifying a model's weaknesses.
Human Performance vs. Models
It's worth noting that human-level accuracy varies on the test. Unspecialized humans from Amazon Mechanical Turk achieve 34.5% accuracy, while expert-level accuracy is estimated to be 89.8%. GPT-3 reaches 43.9% accuracy on average, which is higher than random-chance but still well below expert-level performance.
Pretraining Models on Massive Multitask Test
The scientists evaluated several models on the Massive Multitask Test, including GPT-3 and UnifiedQA. Both models achieved competitive performance without any fine-tuning, which indicates their transfer accuracy. Despite recent progress, state-of-the-art models still have difficulties learning and applying knowledge from pretraining.
Conclusion: Room for Improvement
Overall, the new Massive Multitask Test provides a useful benchmark for assessing a model's broad knowledge and expertise. It highlights the challenges still faced by NLP models, especially regarding learning and applying knowledge from pretraining. By addressing these shortcomings, researchers can develop more effective language models that are better equipped to understand and process information across a wide array of domains.
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Authors: Stephanie Lin, Jacob Hilton, Owain Evans
Source and references: https://arxiv.org/abs/2109.07958v2
A benchmark for measuring truthfulness
As language models become increasingly more common and are deployed for a wide range of practical applications, their ability to generate false statements has become a growing concern. Enter TruthfulQA, a benchmark proposed by researchers at the University of Oxford and OpenAI. This benchmark aims to measure how truthful a language model is by testing how likely it is to generate false answers to 817 carefully crafted questions spanning 38 categories, such as health, law, and finance.
The truthfulness objective
The researchers developed a strict standard in evaluating a model's truthfulness. An answer is considered truthful if it thoroughly avoids asserting any false statements. While an ideal model would provide accurate, informative answers to all questions, the authors state that it is more important to ensure that generated statements are truthful; non-committal responses like "I don't know" or "no comment" are deemed true in their evaluation.
Constructing and validating TruthfulQA
To create the questions for TruthfulQA, the authors first wrote some questions they suspected humans would answer falsely. After filtering questions that their target model, GPT-3, answered consistently correctly, they constructed their final set of 817 questions. They validated this set of questions by involving external researchers and calculating the percentage of questions they might disagree with. The disagreements were around 6-7%, which do not affect the study's main results.
Evaluating language models on truthfulness
Four model families were evaluated on the TruthfulQA benchmark: GPT-3, GPT-Neo/J, GPT-2, and UnifiedQA. The largest models within each family generally performed worse in terms of truthfulness, exhibiting the "inverse scaling" trend. This finding contrasts with other NLP tasks, where larger models often perform better. Moreover, GPT-3-175B, the best-performing model, was truthful on 58% of questions, far lower than the human performance of 94%.
Distinguishing imitative falsehoods
One of the key takeaways from this research is the concept of imitative falsehoods. These are false answers with high likelihood in a model's training distribution. If a model's training objective incentivizes generating false answers, they call these imitative falsehoods. Models often generate answers that mimic popular misconceptions, potentially deceiving users. As models are scaled up, the rate of imitative falsehoods increases, a phenomenon researchers call "inverse scaling." Understanding and addressing imitative falsehoods is crucial to creating more reliable, trustworthy language models.
An automated metric for truthfulness
The study also introduced an automated metric for truthfulness by fine-tuning GPT-3 on human evaluations of whether answers were true or false. This metric achieved a high accuracy of 90-96% on held-out models and serves as a reproducible way to assess the truthfulness of language model outputs.
Conclusions and implications
TruthfulQA highlights the concern of untruthful outputs from large language models. Despite their impressive fluency, these models tend to produce answers that mimic human misconceptions, with potential negative consequences in applications such as legal advice, medical advice, and other high-stakes domains.
Improving a model's truthfulness may not be possible by merely scaling up its size; the research suggests that fine-tuning models using training objectives other than text imitation could prove more promising. By understanding and addressing the issue of imitative falsehoods, researchers can develop more reliable and trustworthy language models, benefiting a wide range of applications.
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Authors: Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, Yejin Choi
Source and references: https://arxiv.org/abs/1907.10641
The Quest for Commonsense Reasoning
Machine learning has come a long way in recent years. We've seen clever algorithms play professional-level video games and models that generate coherent text. But there's one thing that's been particularly challenging for machines: commonsense reasoning. The authors of this paper propose a dataset called WINOGRANDE, a set of 44k problems inspired by the original Winograd Schema Challenge (WSC), a benchmark that was designed to test a machine's commonsense abilities. In particular, the authors wanted to see if these AI models had truly acquired commonsense capabilities or whether they rely on spurious biases in the datasets they trained on.
Adversarial Filtering for Bias Reduction
The authors noticed that existing datasets contain subtle biases that AI models can exploit to reach high levels of performance, even though these models haven't necessarily "understood" the task in a commonsense way. To prevent these biases, they developed a novel algorithm called AFLITE (Algorithmic Filtering Lite) that systematically removes biases from the data. This method uses a lightweight, iterative approach to detect and filter out instances that may contain biases.
Creating WINOGRANDE
How did they do it? First, the authors carefully crafted a crowdsourcing task to generate thousands of WSC-like problems. To encourage creativity and reduce cognitive load for crowd workers, the authors used a concept called "creativity from constraints": workers had to follow specific guidelines on the structure of the curated data, and they were provided with random constraints in the form of topics to inspire their writing.
Next, the data were validated to check if the generated problems met the original requirements of the WSC challenge, i.e., avoiding word association and maintaining a high degree of word overlap between the two answer choices of a pair of problems called "twins."
Finally, they applied their novel AFLITE algorithm to detect and remove instances with unwanted biases. This approach is more broadly applicable than existing methods, and it's also more computationally efficient.
Performance and Implications
With their WINOGRANDE dataset, the authors found that state-of-the-art AI models achieved significantly lower performance than humans. Models like RoBERTa reached accuracies between 59.4% and 79.1% depending on the amount of training data allowed, while humans achieved around 94% accuracy. The authors also demonstrated that WINOGRANDE can provide transfer learning to other existing benchmarks and achieve state-of-the-art results in five related tasks.
Here's the catch: while the improvements in performance are impressive, they should be taken with a grain of salt. The authors emphasize that these positive results may also highlight the extent to which spurious effects, or biases, are prevalent in the datasets used to train these models. This means we may be overestimating the true capabilities of machine intelligence across these benchmarks.
The authors argue that human-crafted problems and tasks in machine learning often contain dataset biases and that algorithmic bias reduction, such as AFLITE, is essential to mitigating these biases and improving the fairness and robustness of machine learning models.
Relevant Progress and Future Directions
Past research has pointed out that dataset biases are pervasive in machine learning, impacting the performance and fairness of models in natural language processing and other domains. This paper's contribution, AFLITE, adds to a growing body of work on adversarial learning techniques that aim to address these issues, from hypothesis-only biases in natural language inference to general biases across various datasets.
Ultimately, this work highlights a crucial aspect of machine learning research: the need for not just well-crafted datasets but also carefully designed algorithms that are robust to biases, especially when tackling commonsense reasoning tasks. Only then can the true capabilities of AI models be accurately assessed and the potential ethical and social implications of biased models be mitigated.
Training Verifiers to Solve Math Word Problems
Authors: Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, John Schulman, OpenAI
Source and references: https://arxiv.org/abs/2110.14168
A New Dataset to Test Language Models
In recent years, language models have made significant strides in a wide range of tasks, but they still struggle with multi-step mathematical reasoning. To diagnose these failures and support research, the authors introduce a new dataset called GSM8K, featuring 8.5K high-quality, linguistically diverse grade school math word problems.
State-of-the-art language models, like GPT-3, often fail on this dataset despite its conceptual simplicity. Designing methods to improve performance on math word problems remains a challenge, and this paper proposes a promising solution.
Tackling Math Word Problems with Verifiers
The researchers decided to train "verifiers" that can evaluate the correctness of model-generated solutions. Instead of relying only on generative methods, the idea is to sample multiple candidate solutions at test time and use the verifier to rank them. The solution with the highest rank is then chosen as the final answer.
To facilitate this approach, the authors fine-tune a language model, called the "generator," on the GSM8K dataset for a few epochs. They then use the generator to sample 100 completions for each problem in the dataset. Finally, the verifier is trained on the completions, labeled as correct or incorrect based on whether they reach the correct final answer. Separate generator and verifier models are used to prevent the generator from overfitting.
Comparing Verifiers to Finetuning Baseline
The authors used models from the GPT-3 family for both fine-tuning and verification. GPT-3 models were fine-tuned for 2 epochs on the training set, and verifiers were then trained for a single epoch on the generated solutions. The verifier's main task is to judge solutions' correctness, but it's also trained with the same language modeling objective as the generator.
When compared to a fine-tuning baseline, the verification method shows significant improvement for both 6B and 175B model sizes, especially on larger datasets. The authors found that the 175B verifiers "take off" earlier than the 6B verifiers, requiring fewer training problems to surpass the fine-tuning baseline.
Interesting Findings and Ablations
The researchers explored various aspects of the verification method through ablations. They found that predicting the value function at every token in the generated solution (token-level value function) performed better than making a single scalar prediction for the entire solution (solution-level value function).
The authors also investigated the performance of the verifiers when trained jointly for predicting correctness and performing language modeling. The joint approach proved more effective, providing a valuable auxiliary objective for the verifier. Additionally, they explored the impact of varying the sizes of the generator and verifier models. Increasing the size of the generator had a larger impact on performance than increasing the size of the verifier.
Implications and Future Directions
This paper demonstrates that using verifiers to evaluate the correctness of language model-generated solutions can significantly improve performance on math word problems like those in the GSM8K dataset. By sampling multiple candidate solutions and selecting the highest-ranked one, the verifier method offers a more robust approach to solving multi-step mathematical reasoning tasks.
While the authors focus on natural language solutions and maintain separate generator and verifier models, future work could explore the potential benefits of combining the models or using specialized architectures. As language models continue to grow in size and performance, incorporating verification techniques like the ones proposed in this paper may be crucial for achieving robust, error-free mathematical reasoning.
As we conclude our exploration of the benchmarks on the OpenLLM Leaderboard, we hope this post has provided valuable insights into the capabilities and limitations of current open-source language models. Understanding these benchmarks is crucial for advancing the field of AI and for the development of more sophisticated and ethical language models in the future.
For further reading and to dive deeper into the world of language model benchmarks, we encourage you to explore the links provided below. These resources will offer additional perspectives and detailed information, enhancing your knowledge and understanding of this rapidly evolving field.
Stay tuned to State of AI for more updates and analyses on the latest trends and developments in artificial intelligence and machine learning. Your engagement and feedback are invaluable as we continue to navigate this exciting technological landscape together.