

A Cognitive Framework for Efficient Long-Term Memory in LLMs
Designing LLMs that remember efficiently without sacrificing performance

Large Language Models (LLMs) have achieved impressive performance across a wide range of reasoning and generation tasks. Yet, they remain constrained by a key architectural limitation: their inability to efficiently retain and leverage prior interactions in dynamic, long-context settings. The root causes are twofold, fixed context windows that cap recall capacity, and the “lost in the middle” effect, where essential information buried deep within long sequences fades from the model’s usable memory.
Turn Ideas Into Decks That Impress

Struggling to turn your ideas into great slides? Presentations.ai is like ChatGPT for presentations. Just describe your topic, and our AI instantly builds stunning, story-driven decks that look professionally designed. No templates, no formatting, no wasted hours.
You bring the ideas; we handle the design. Start building presentations that actually make people pay attention. Build your first AI-powered deck today.
To overcome these constraints, recent research has turned toward external memory systems that extend an LLM’s contextual reach beyond its native attention span. However, current implementations often introduce new challenges, from retrieval inefficiencies and high latency to memory inconsistency and stale information, leaving the problem of persistent, reliable memory for LLMs far from solved.
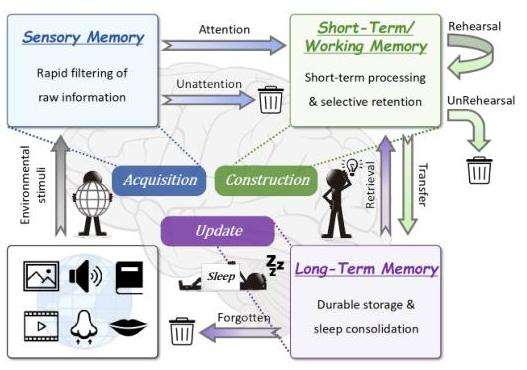
The paper LightMem: Lightweight and Efficient Memory-Augmented Generation introduces LightMem, a memory architecture inspired by the Atkinson–Shiffrin model of human memory. It presents a practical approach to extending LLM memory without the heavy computational overhead typical of existing systems. While many frameworks maximize effectiveness through large-scale retrieval or dense storage, LightMem pursues a balanced design, preserving performance while dramatically improving efficiency and scalability.
Core Architecture and Methodology
LightMem structures its memory system into three stages that parallel the human cognitive process: Light1 (Sensory Memory), Light2 (Short-Term Memory), and Light3 (Long-Term Memory). This layered design allows information to be filtered, organized, and consolidated efficiently as it moves through the pipeline.
Light1: Sensory Memory and Preprocessing
The sensory memory stage performs rapid initial filtering through two key components:
Pre-Compression Module: This module removes redundant tokens using LLMLingua-2 as the compression model. For each input token in a sequence, the model generates a vector and computes a retention probability that determines whether each token should be preserved or discarded.
This preprocessing step ensures that only the most relevant contextual information advances to the next stage, minimizing computational overhead without sacrificing accuracy.
Topic Segmentation Module: Pre-compressed information is then grouped into semantically coherent segments using a hybrid method that combines attention-based and similarity-based criteria. The model constructs a turn-level attention matrix MMM and identifies boundaries..
This adaptive segmentation yields more meaningful memory units than fixed-window approaches, aligning the stored content with conversational and semantic structure.
Topic-Aware Short-Term Memory
In the second stage, LightMem consolidates topic segments into structured summaries. Each segment is represented as {topic, message turns} and stored in a Short-Term Memory (STM) buffer. When the buffer reaches a preset token limit, an LLM summarizes each entry into compact representations.
This design maintains topical coherence while dramatically reducing the size of active memory.
Long-Term Memory with Sleep-Time Updates
The Long-Term Memory (LTM) layer introduces a decoupled update mechanism that separates inference from memory maintenance:
Soft Updating: During inference, new memory entries are appended with timestamps, avoiding costly real-time updates that risk latency or data loss.
Sleep-Time Updates: During offline periods, the system consolidates knowledge through reflective updates. For each stored entry with an embedding and timestamp, an update queue identifies the top most semantically similar entries with later timestamps. Since these queues operate independently, updates can run in parallel, reducing total update latency by orders of magnitude.
Experimental Evaluation
LightMem was evaluated on LONGMEMEVAL-S, a dataset containing 500 dialogue histories averaging 115,000 tokens each. Baselines included Full Text, Naive RAG, LangMem, A-Mem, MemoryOS, and Mem0.
Effectiveness and Efficiency
LightMem achieved consistent gains across both performance and efficiency metrics:
Accuracy: Outperformed the strongest baseline (A-Mem) by 2.7%–9.65% using GPT-4o-mini, and up to 7.67% with Qwen3-30B-A3B-Instruct-2507.
Efficiency:
Token usage reduced by 32×–106× for GPT-4o-mini and 29×–117× for Qwen.
API calls reduced by 17×–159× for GPT-4o-mini and 19×–177× for Qwen.
Runtime improved between 1.67× and 12.45×.
Component Analysis
Ablation studies confirmed the contribution of each module:
Pre-Compression: Performance remained stable with compression ratios between 50% and 80%. The optimal ratio varied with STM buffer size—smaller buffers performed best
Topic Segmentation: The hybrid segmentation approach achieved over 80% accuracy in identifying topic boundaries. Removing it reduced accuracy by 6.3% for GPT and 5.4% for Qwen, underscoring its importance for semantic organization.
Sleep-Time Updates: The decoupled update mechanism prevented information loss common in real-time LLM updates and enabled parallel consolidation during offline phases.
Technical Contributions
LightMem introduces several key advances over prior memory-augmented systems:
Cognitive-Inspired Design: Modeled after the Atkinson–Shiffrin framework, LightMem balances retention and efficiency through progressive information filtering.
Hybrid Topic Segmentation: Combining attention- and similarity-based cues produces semantically coherent segments, reducing topic drift and improving retrieval accuracy.
Decoupled Memory Maintenance: By separating inference from consolidation, the system achieves both responsiveness and long-term stability.
Parallel Update Architecture: Independent queues enable concurrent memory updates, dramatically reducing maintenance overhead.
Significance and Broader Impact
LightMem demonstrates that efficiency and effectiveness need not be opposing goals in memory-augmented LLMs. With up to 117× reductions in token usage and 177× fewer API calls, it makes persistent, high-quality memory feasible for large-scale, real-world deployment.
Its cognitive foundation provides a natural framework for handling information flow over time, addressing long-standing issues such as information loss and inconsistency in external memory systems. The architecture scales gracefully to extended dialogues while preserving semantic structure, enabling the next generation of AI systems that can reason, recall, and adapt continuously.
For the broader AI community, LightMem opens the door to more capable and cost-efficient agents, systems that maintain contextual continuity across interactions and evolve with use. The efficiency gains also lower operational barriers, making advanced memory architectures more accessible to both research and industry.
++ Good Post, Also, start here stock market, AI research, Crash Courses, 100+ Most Asked ML System Design Case Studies and LLM System Design
Stock Market
https://open.substack.com/pub/stockmarketanalysis04/p/important-stock-market-post-04-which?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/stockmarketanalysis04/p/important-stock-market-analysis-which?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/stockmarketanalysis04/p/important-stock-market-post-02-understand?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/stockmarketanalysis04/p/important-stock-market-post-03-this?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
Crash Courses
https://open.substack.com/pub/crashcourses/p/crash-course-02-a-complete-crash?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/crashcourses/p/crash-course-01-a-complete-crash?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
AI/ML Research
https://open.substack.com/pub/airesearch04/p/ai-research-2-kimi-k2-thinking-a?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/airesearch04/p/ai-research-1-the-transformer-revolution?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
LLM System Design
https://open.substack.com/pub/naina0405/p/most-important-llm-system-design-b31?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://naina0405.substack.com/p/launching-llm-system-design-large?r=14q3sp
https://naina0405.substack.com/p/launching-llm-system-design-2-large?r=14q3sp
[https://open.substack.com/pub/naina0405/p/llm-system-design-3-large-language?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/important-llm-system-design-4-heart?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
System Design
https://open.substack.com/pub/naina0405/p/system-design-tech-case-study-pulse-862?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/system-design-tech-case-study-pulse-b3c?r=14q3sp&utm_campaign=post&utm_medium=web
https://open.substack.com/pub/naina0405/p/system-design-tech-case-study-pulse-135?r=14q3sp&utm_campaign=post&utm_medium=web
https://open.substack.com/pub/naina0405/p/system-design-tech-case-study-pulse-007?r=14q3sp&utm_campaign=post&utm_medium=web